
Implementando um Neurônio Artificial do Zero
 Maurício Taffarel
Maurício TaffarelIntrodução
A aprendizagem de máquina (Machine Learning) tem ganhado destaque nos últimos anos. Vivemos num mundo em que cada vez mais as inteligências artificiais estão mais presentes. Assistentes virtuais, carros autônomos, reconhecimento facial, detectores de spam, sistemas de recomendação, atendimento ao cliente, GPS com monitoramento de trânsito em tempo real e até mesmo o seu uso na medicina são alguns dos exemplos de aplicação da inteligência artificial no nosso dia a dia.
Além disso, pode-se notar um crescimento no número de artigos em conferências, periódicos e revistas que tratam sobre o tema além do interesse das suas aplicações na Indústria 4.0. Segundo dados do IDC (2021), entre as organizações de grande porte no Brasil, cerca de 1/4 delas já estão utilizando IA e Machine Learning (ML) em projetos próprios. Além disso, os gastos com IA no Brasil chegarão ao total de US$ 464M em 2021idc.
Este artigo tem como finalidade apresentar uma rede neural mais basal, o Perceptron, seu modelo matemático, como ocorre o processo de aprendizagem, o algoritmo que o implementa e como ele pode ser utilizado para classificação binária.
Neurônio
O neurônio biológico
O neurônio biológico é uma célula com uma função especializada na transmissão de informações. Os neurônios são capazes de receber e transmitir impulsos nervosos para outros neurônios através das sinapses químicas e elétricas. Este tipo de célula apresentam diversas estruturas, dentre as quais, podemos citar quatro estruturas principais de acordo com as suas funções.livrobio
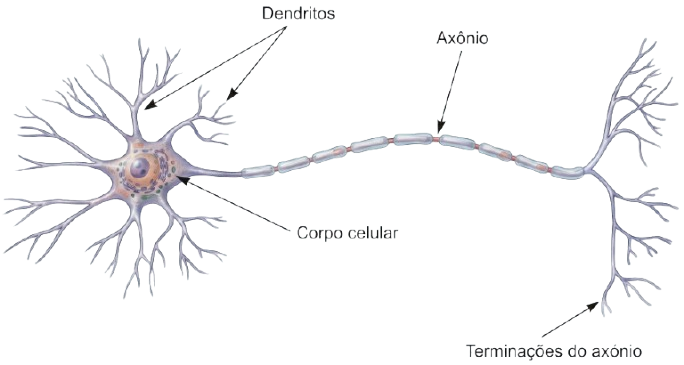
Estrutura do neurônio biológicoimgneuronio
- Os dendritos são um conjunto de ramificações responsáveis por receber impulsos nervosos de outros neurônios e por transmitir para o corpo celular.
- O corpo celular é a parte do neurônio que contém o núcleo e o citoplasma que envolve o núcleo. Esta estrutura é responsável por receber os impulsos nervosos dos dendritos e processar a informação, os sinais recebidos podem ser excitatórios ou inibitórios e a soma destes sinais determina se o neurônio vai ser excitado e se irá disparar um impulso nervoso para o axônio.
- E por último, o axônio é responsável pelo transporte deste sinal até as terminações do axônio, que por sua vez, transmite estes sinais às células-alvo que são outros neurônios, ou até mesmos para músculos ou glândulas.sinapsesbio
Desta forma, os neurônios estão conectados a outros neurônios através de estruturas complexas formando circuitos que juntos são capazes de processar informações formando as redes neurais.
O neurônio matemático
Inspirado no que se sabia até o momento sobre o cérebro humano e o modelo do neurônio, foram realizadas diversas tentativas de realizá-lo matematicamente. O primeiro modelo que se tem registros é o dos pesquisadores McCulloch e Pitts no ano de 1943.historiaia Mais tarde, inspirado nas pesquisas destes pesquisadores, em 1958, o cientista Frank Rosenblatt desenvolveu o que o mesmo denominou como Perceptronperceptronrosenblatt.

Perceptron Mark I, desenvolvido por Frank Rosenblatt em 1958perceptronrosenblatt
Este modelo realiza uma soma ponderada de diversas entradas e calcula a saída através de uma função de ativação.
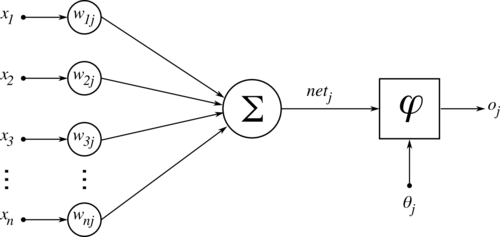
Estrutura do neurônio artificialimgneuronioartificial
Os impulsos elétricos dos neurônios no modelo artifical são representados pelas entradas . Há entradas que excitam mais ou menos o neurônio artificial. A influência de cada entrada é determinada pelos pesos sinápticos onde se refere ao neurônio de estudo e ao peso do terminal de entrada de mesmo índice, estes pesos podem ter diferentes intensidades (valor do peso), assim como sua característica excitatória ou inibitória (através do sinal do peso).
O corpo celular é representado pelo somatório das entradas com seus respectivos pesos sinápticos, que serão aplicadas na função de ativação , adicionando também como argumento, um limiar de ativação para então produzir a saída do neurônio , que seria em um neurônio biológico, a resposta do impulso enviada para o axiônio.
Assim, podemos definir que a variável apresentará um valor que seria uma média ponderada dos inputs com os pesos sinápticos:
A saída do neurônio artifical é dada pela função de ativação aplicada ao valor do somatório e ao limiar de ativação :
Algumas simplificações podem ser feitas para o caso do Perceptron e para facilitar a implementação computacional no próximo tópico. Como o limiar de ativação é somado ao somatório na função de ativação, então, incorpora-se este limiar a função :
Geralmente a função de ativação que determina a saída do neurônio artifical é escolhida de forma que , como o Perceptron é utilizado para reconhecimento de padrões e classificação de dados, entre duas amostras, sua saída apresenta duas possibilidades de valores: verdadeiro ou falso, podendo ser representado pela função degrau ou degrau bipolar, neste caso consideramos a função degrau bipolar para determinar a saída:
Neste caso, o limite da condição ou threshold é definido quando , ou seja, quando:
Ao considerar , o Perceptron possui duas entradas com pesos sinápticos constantes () e viés constante, resultando na seguinte equação de decisão:
Fica claro que a fronteira de decisão do Perceptron é uma equação linear, podendo separar classes de amostras (desde que sejam separáveis).
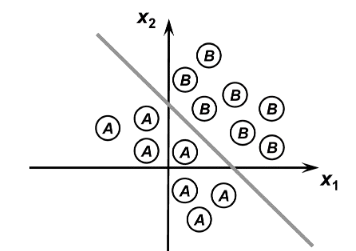
Classificação de entradas para n=2 imgclassificacao
A extrapolação pode ser feita para outros valores de , para o caso de (3 dimensões) tem-se um plano para o fronteira de classificação, para valores superiores, um hiperplano.
Treinamento do Perceptron
O processo de aprendizagem de um Perceptron se dá através do ajuste de pesos sinápticos. Tomando um conjunto de amostras de entradas e de saídas, diz-se que uma rede neural “aprendeu”, quando é capaz de determinar os pesos sinápticos e o limitar de ativação de tal forma que para todas (ou para quase todas) as entradas de amostras, as saídas determinadas pelo neurônio artificial são iguais às saídas de amostra. O processo de aprendizagem de uma rede neural é chamado de treinamento.
O processo de treinamento pode ser realizado de acordo com a regra de aprendizado de Hebb:
When an axon of cell A is near enough to excite a cell B and repeatedly or persistently takes part in firing it, some growth process or metabolic change takes place in one or both cells such that A’s efficiency, as one of the cells firing B, is increased.hebb
O algoritmo, a cada iteração, incrementa (ou decrementa) aos pesos e ao limiar de ativação um valor proporcional à diferença entre a saída obtida e a saída esperada e aos sinais de entrada caso estas saídas tenham valores diferentes. Este processo é repetido até que todas as amostras (ou boa parte delas) para o treinamento tenham as respostas de saídas iguais às respostas esperadas.
Matematicamente isso pode ser definido como:
Nestas equações foram omitidos os índices referentes ao neurônio em questão e ao parâmetro temporal, para simplificação, buscamos a implementação computacional de apenas um Perceptron com pesos sinápticos invariantes no tempo.
O valor desejado da amostra é denominado como . Além disso, nota-se a presença de um fator no incremento (ou decremento) dos pesos e limiar, este fator é denominado taxa de aprendizagem, que define a velocidade de convergência do treinamento, quanto maior esta taxa, mais rápido a rede aprenderá e vice e versa, contudo, um muito grande pode causar instabilidades no processo de treinamento, normalmente a taxa de aprendizagem da rede é escolhido entre o intervalo .
Algoritmo do Perceptron
Como o limiar de ativação também é uma variável de ajuste, podemos tratar esta variável como se fosse um peso sináptico simplificado as equações anteriores para a equação abaixo:
E em notação computacional:
onde:
A implementação do computacional pode ser feita de acordo com o seguinte algoritmo:
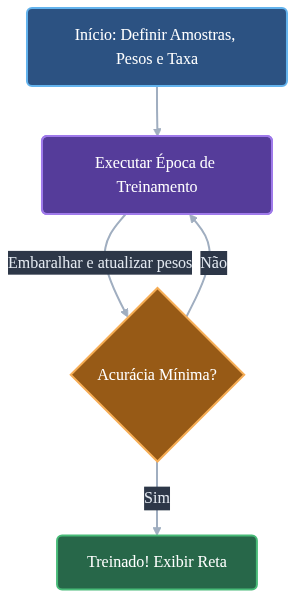
Algoritmo de treinamento do Perceptron
Implementação computacional
Preparando o ambiente
Uma vez determinado o algoritmo, segue-se para usa implementação. A linguagem de programação utilizada será o R. Para garantir a reprodutibilidade deste experimento e visualizar os gráficos sem precisar instalar o R localmente, utilizaremos um container Docker com o RStudio Server.
Com o Docker instalado, execute o seguinte comando no terminal para baixar e executar o container:
docker run --rm -ti \
-e PASSWORD=senhasegura \
-p 8787:8787 \
rocker/rstudioCom o container em execução, abra seu navegador e acesse http://localhost:8787. Você verá a tela de login do RStudio Server.
Utilize as credenciais que definimos no comando anterior:
- Username:
rstudio - Password:
senhasegura
Dentro da interface, vá até o menu superior e selecione File > New File > R Script caso queira criar um script ou cole os códigos a seguir no Console. Os gráficos aparecerão no painel Plots, no canto inferior direito.
Definindo amostras
O primeiro passo consiste em se gerar aleatoriamente dois conjuntos de amostras, para este exemplo, as classes serão bolas verdes e vermelhas. O seguinte trecho de código gera 100 bolas verdes e vermelhas pseudo aleatoriamente através de uma distribuição uniforme:
N = 50 # Número total de pontos de cada classe
verde_x = runif(N, min = 0.4, max = 1)
verde_y = runif(N, min = 0.4, max = 1)
vermelho_x = runif(N, min = 0, max = 0.6)
vermelho_y = runif(N, min = 0, max = 0.6)
amostras_x = c(verde_x, vermelho_x)
amostras_y = c(verde_y, vermelho_y)
amostrasSaidas = c(rep(-1,N), rep(1,N))
par(pty="s")
plot(amostras_x, amostras_y, main='Amostras iniciais',
type='n', xlab='X', ylab='Y')
points(verde_x, verde_y, col='green')
points(vermelho_x, vermelho_y, col='red')Um resultado para a execução do código anterior é:
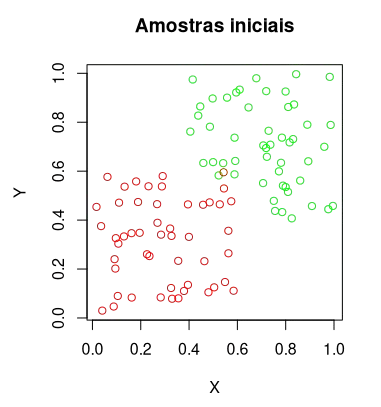
Dados iniciais para o treinamento
Seguindo o algoritmo, inicia-se o vetor pesos sinápticos, define-se a taxa de aprendizagem e a acurácia de parada.
w0 = 0.1 # Limiar de ativação
w1 = 0.2 # Peso x inicial
w2 = 0.3 # Peso y inicial
M = 50 # Numero de épocas
eta = 0.1 # Taxa de aprendizagem da rede
ac = 0.93 # Acurácia para parar
temErro = F # Flag para imprimir respostasTreinamento do Perceptron
Para fazer o treinamento, usa-se a contagem das épocas e duas condições para paradas: 1) Obter uma acurácia igual ou superior da desejada; 2) Limite de épocas alcançado.
# Iteração por época
for (i in 1:M){
print(paste('Época: ', i))
# Embaralhamento das amostras
index = 1:(2*N)
index = sample(index)
# Iteração por amostra
for (j in index){
# Cálculo da saída do Perceptron
u_j = w0 + w1*amostras_x[j] + w2*amostras_y[j]
# Função de ativação degrau bipolar
if (u_j >= 0){
y_j = 1
} else {
y_j = -1}
# Atualização dos pesos sinápticos
w0 = w0 + eta*(amostrasSaidas[j] - y_j)*1.0
w1 = w1 + eta*(amostrasSaidas[j] - y_j)*amostras_x[j]
w2 = w2 + eta*(amostrasSaidas[j] - y_j)*amostras_y[j]
# Impressão dos pesos atualizados
if (temErro == T){
print(paste(' -> Atualizando ', j, ' : '))
print(paste(' -> w0: ' ,w0))
print(paste(' -> w0: ' ,w1))
print(paste(' -> w0: ' ,w2))
}
}
# Cálculo da acurácia ao final da época
y_all = w0 + w1*amostras_x + w2*amostras_y
y_pred = y_all
y_pred[y_all >= 0] = 1
y_pred[y_all< 0] = -1
acc = sum(y_pred == amostrasSaidas)/length(amostrasSaidas)
print(paste('Final da época: ', i, ' com: ', 100*acc, '% de acurácia'))
# Verificação da condição de parada
if (acc >= ac){
break
}
}Ao fim da execução deste código, espera-se que o algoritmo tenham conseguido ajustar os pesos sinápticos e o limiar de ativação apresentando boa acurácia (maior ou igual que a desejada).
Exibindo a reta de classificação
Por último, para exibir a reta que define o limiar de classificação, executamos o último trecho de código:
# Predição final
y_all = w0 + w1*amostras_x + w2*amostras_y
y_pred = y_all
y_pred[y_all >= 0] = 1
y_pred[y_all< 0] = -1
# Cálculo da acurácia final
acc = sum(y_pred == amostrasSaidas)/length(amostrasSaidas)
# Exibição da reta de classificação
plot(main='Reta de classificação obtida', amostras_x, amostras_y,
type='n', xlab='X', ylab='Y')
points(verde_x, verde_y, col='green')
points(vermelho_x, vermelho_y, col='red')
abline(a = -1.0*w0/w2, b = -1.0*w1/w2, col='purple', lwd=3, lty=2)
legend(0,1,legend = acc, col='purple', lwd=3)
print (acc)Um possível resultado obtido é: 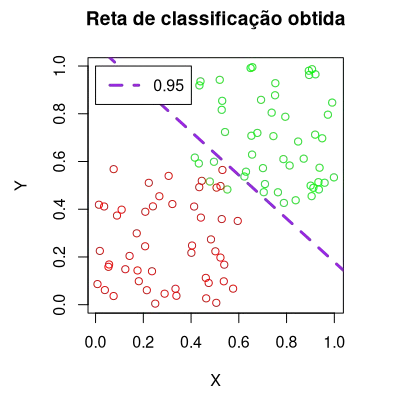
Conclusão
Neste artigo, navegamos desde a lógica algorítmica do Perceptron até sua implementação prática em R, visualizando como a máquina “aprende” a traçar uma reta separadora entre duas classes de dados. O gráfico final com a acurácia desejada demonstra a convergência do algoritmo, validando que os pesos sinápticos foram ajustados corretamente através das épocas de treinamento
Experimente modificar os parâmetros, como a taxa de aprendizagem, o número de épocas e a acurácia desejada para observar como eles influenciam o processo de treinamento e a performance do Perceptron.
- 10 PREVISÕES DE TIC PARA 2021, 2021, Online. Evento […]. [S. l.: s. n.], 2021. Disponível em: https://www.idclatin.com/2021/events/02_04_br/na.html. Acesso em: 6 set. 2021.↩
- David E. Sadava, David M. Hillis, H. Craig Heller, and May Berenbaum, “How Do Neurons Communicate with Other Cells?” em Life: The Science of Biology, 9th ed. (Sunderland: Sinauer Associates, 2009), 961.↩
- Disponível em: ”https://www.sobiologia.com.br/conteudos/FisiologiaAnimal/nervoso2.php”. Acesso em 8 set. 2021.↩
- Alberto E. Pereda, “Electrical Synapses and Their Functional Interactions with Chemical Synapses,” Nature Reviews Neuroscience 15 (2014): 250-263, https://dx.doi.org/10.1038/nrn3708.↩
- Jürgen Schmidhuber, Deep learning in neural networks: An overview, Neural Networks, Volume 61, 2015, Pages 85-117, ISSN 0893-6080, https://doi.org/10.1016/j.neunet.2014.09.003.↩
- Rosenblatt, F. (1958). The perceptron: A probabilistic model for information storage and organization in the brain. Psychological Review, 65(6), 386–408. https://doi.org/10.1037/h0042519↩
- Disponível em: ”https://commons.wikimedia.org/wiki/File:ArtificialNeuronModel.png”. Acesso em 8 set. 2021.↩
- Silva, Ivan Nunes da Redes neurais artificiais: para engenharia e ciências aplicadas / Ivan Nu-nes da Silva; Danilo Hernane Spatti; Rogério Andrade Flauzino. – São Paulo: Artliber, 2010.↩
- Hebb, D. O. (1949). The organization of behavior. New York: Wiley. 1949, pag 62↩